Integration with Dask¶
Dask is a powerful and flexible tool for scaling Python analytics across a cluster. Dask works out-of-the-box with JupyterHub, but there are several things you can configure to make the experience nicer.
Install Dependencies¶
To run Dask on Hadoop you’ll need to install dask-yarn in the notebook environment.
# Install with conda
$ conda install -c conda-forge dask-yarn
# Or install with pip
$ pip install dask-yarn
Install Optional Dependencies¶
For a nicer UI experience and access to the Dask Dashboard, you’ll also want to install jupyter-server-proxy and ipywidgets in the notebook environment.
# Install with conda
$ conda install -c conda-forge jupyter-server-proxy ipywidgets
# Or install with pip
$ pip install jupyter-server-proxy ipywidgets
Configuration¶
While Dask will work as long as dask-yarn is installed, as an administrator
you can preconfigure a few default fields to make things easier for your users.
Dask’s default configuration is collected from the following locations (earlier sources taking precedence):
- Environment variables like
DASK_YARN__ENVIRONMENT - YAML files found in
$DASK_CONFIG(defaults to~/.config/dask/) - YAML files found in
<ENV>/etc/daskwhere<ENV>is a user’s Conda/Virtual environment - YAML files found in the system
/etc/dask/directory - Default settings within the various dask libraries
As such, you have a few options for how to pass configuration on to your users.
If you’re using archived notebook environments,
a good option is to put configuration in <ENV>/etc/dask/config.yaml (where
<ENV> is the top-directory of the environment). This allows having
different configuration settings for different environemnts. These can also be
combined with environment variables set via YarnSpawner.environment (useful
for things determined at runtime, or overrides for the static config files).
Below we provide an example configuration file:
yarn:
# Specify the default Python environment to use for the workers.
# In most cases this should be the same as the environment used for the
# user's notebook server.
# Here we use an archived environment stored on hdfs
environment: hdfs:///jupyterhub/example.tar.gz',
# To instead specify an environment already on every node, use
# environment: local:///path/to/environment
# The YARN queue to submit applications to by default
queue: dask
# Configure the default worker vcores and memory
# These can be overridden by the user as needed
worker:
vcores: 2
memory: 2 GiB
# Use `local` deploy mode. This runs the scheduler in the same container
# as the notebook, and allows for viewing the dashboard using
# jupyter-server-proxy.
deploy-mode: local
distributed:
dashboard:
# Configure the link template for the dask dashboard. This updates the
# dashboard links to proxy through jupyter-server-proxy
link: /user/{JUPYTERHUB_USER}/proxy/{port}/status
The above are likely parameters you’ll want to set, but Dask has many more configuration options. For more information see the Dask configuration documentation.
Usage¶
Given a fully configured system, users should be able to create a Dask Cluster as follows:
import dask_yarn
cluster = dask_yarn.YarnCluster()
Default parameters can be overridden by specifying them at runtime:
import dask_yarn
# Use different worker resources than the default
cluster = dask_yarn.YarnCluster(
worker_vcores=4,
worker_memory='4 GiB'
)
Users can then connect to their cluster and start doing work:
from dask.distributed import Client
client = Client(cluster)
# Start doing computations
import dask.dataframe as dd
ddf = dd.read_parquet("hdfs:///path/to/my/data.parquet")
Clusters can be scaled dynamically at runtime:
# Scale up to 10 workers
cluster.scale(10)
# Scale down to 4 workers
cluster.scale(4)
If you installed jupyter-server-proxy and ipywidgets you’ll also get a
nice UI for interacting with the cluster:
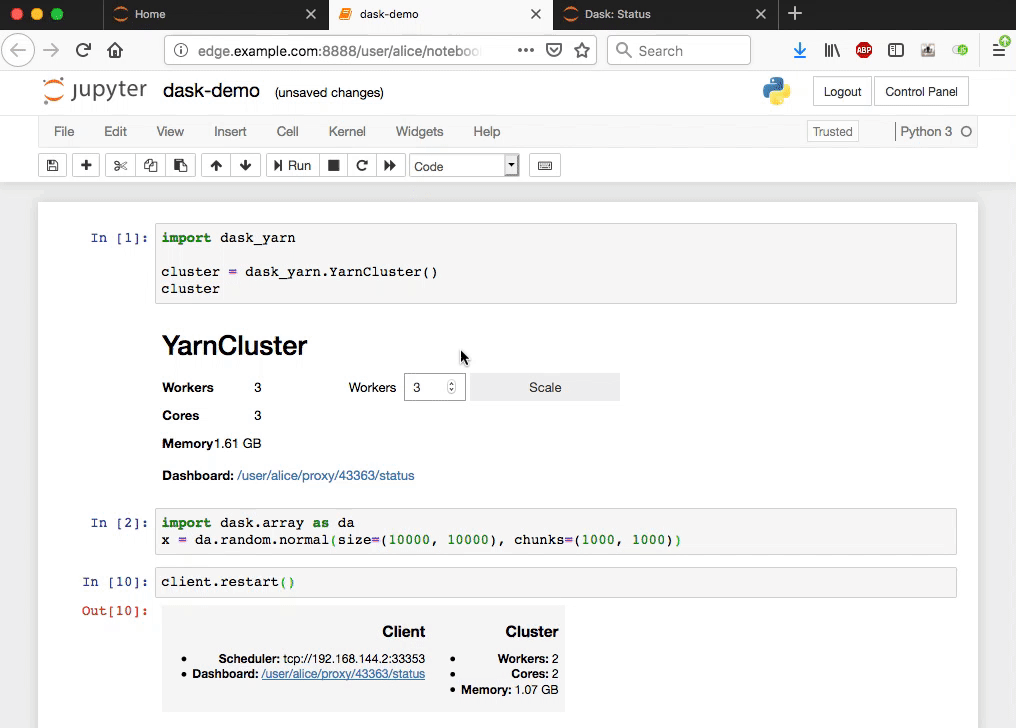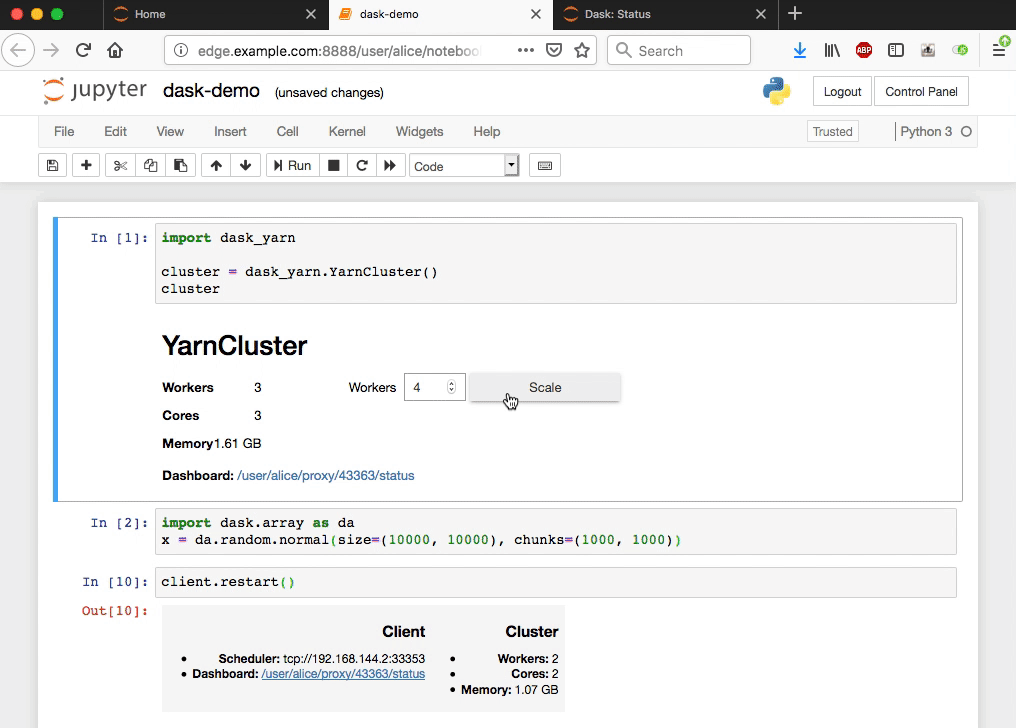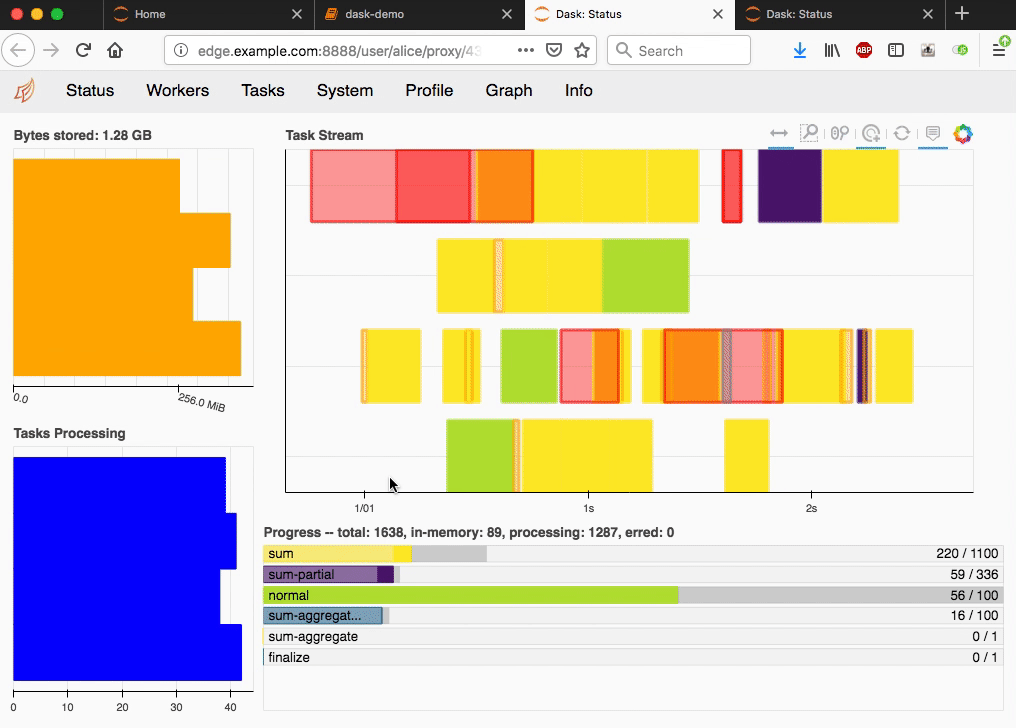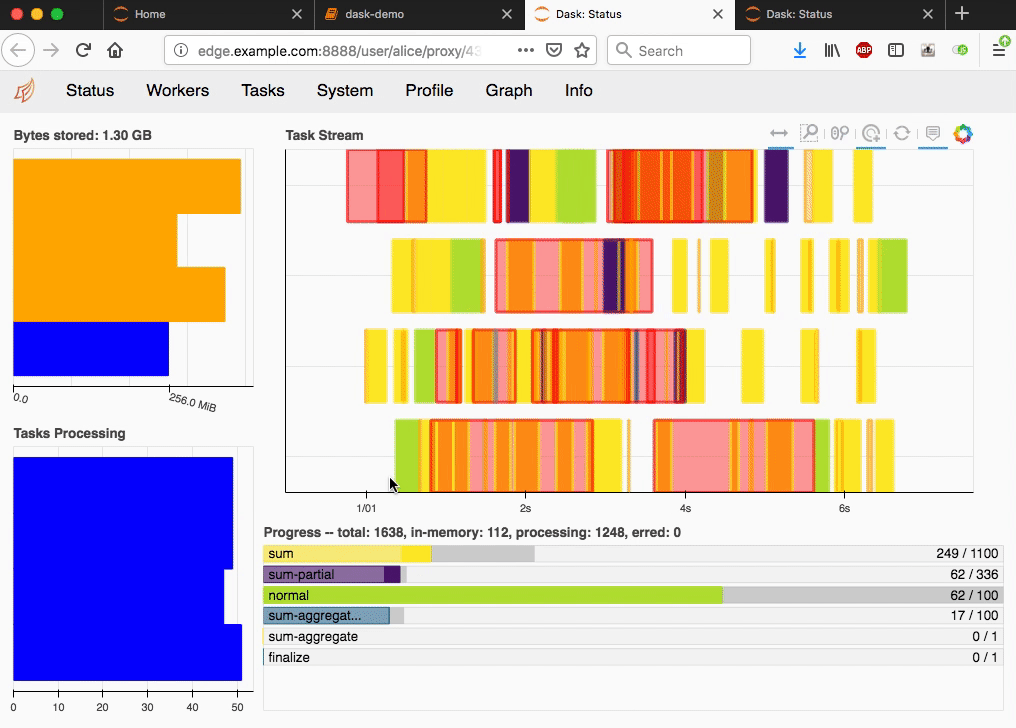
Clusters can be shutdown manually, or will be automatically shutdown on notebook exit.
Further Reading¶
Dask integrates well with the extensive Python datascience ecosystem. For more information please see the following resources:
